问题
问题的本质即基于花卉特征将鸢尾花数据归入不同的组。 这些特征包括:花萼的长度和宽度以及花瓣的长度和宽度。 需通过这些特征了解数据集的结构,并预测数据实例与此结构的拟合相似分类。
创建控制台应用程序
- 打开 Visual Studio。 从菜单栏中选择“文件” > “新建” > “项目”。 在“新项目”对话框中,依次选择“Visual C#”和“.NET Core”节点。 然后,选择“控制台应用程序(.NET Core)”项目模板。 在“名称”文本框中,键入“MLNet”,然后选择“确定”按钮
- 在项目中创建一个名为“数据”的目录来保存数据集和模型文件:
在“解决方案资源管理器”中,右键单击项目,然后选择“添加” > “新文件夹”。 键入“Data”,然后按 Enter。 - 安装“Microsoft.ML NuGet”包:
在“解决方案资源管理器”中,右键单击项目,然后选择“管理 NuGet 包”。 选择“nuget.org”作为包源,然后选择“浏览”选项卡并搜索“Microsoft.ML”,选择列表中的“v0.11.0”包,再选择“安装”按钮。 选择“预览更改”对话框上的“确定”按钮,如果你同意所列包的许可条款,则选择“接受许可”对话框上的“我接受”按钮。
准备数据
- 下载 iris.data 数据集并将其保存至在上一步中创建的“data”文件夹。 若要详细了解鸢尾花数据集,请参阅鸢尾花数据集维基百科页面,以及该数据集的源鸢尾花数据集页面。
- 在“解决方案资源管理器”中,右键单击“iris.data”文件并选择“属性” 在“高级”下,将“复制到输出目录”的值更改为“如果较新则复制”。
该 iris.data 文件包含五列,分别代表以下内容:
- 花萼长度(厘米)
- 花萼宽度(厘米)
- 花瓣长度(厘米)
- 花瓣宽度(厘米)
- 鸢尾花类型
创建数据类
创建输入数据和预测类:
- 在“解决方案资源管理器”中,右键单击项目,然后选择“添加” > “新项”。
- 在“添加新项”对话框中,选择“类”并将“名称”字段更改为“IrisData.cs”。 然后,选择“添加”按钮。
- 将以下
using指令添加到新文件:using Microsoft.ML.Data;
删除现有类定义并向“IrisData.cs”文件添加以下代码,其中定义了两个类 IrisData 和 ClusterPrediction:
/// <summary>
/// 数据类
/// </summary>
public class IrisData
{
/// <summary>
/// 花萼长度
/// </summary>
[LoadColumn(0)]
public float SepalLength;
/// <summary>
/// 花萼宽度
/// </summary>
[LoadColumn(1)]
public float SepalWidth;
/// <summary>
/// 花瓣长度
/// </summary>
[LoadColumn(2)]
public float PetalLength;
/// <summary>
/// 花瓣宽度
/// </summary>
[LoadColumn(3)]
public float PetalWidth;
/// <summary>
/// 预测类型
/// </summary>
[LoadColumn(4)]
public string FlowerType;
}
/// <summary>
/// 预测类
/// </summary>
public class ClusterPrediction
{
/// <summary>
/// 包含所预测的群集
/// </summary>
//[ColumnName("PredictedLabel")]
//public string PredictedClusterId;
//预测输出类型
public string PredictedLabelPlant;
/// <summary>
/// 列包含一个数组,该数组中的数与群集形心之间的距离为欧氏距离的平方。
/// 该数组的长度等于群集数。
/// </summary>
[ColumnName("Score")]
public float[] Distances;
}
IrisData 是输入数据类,并且具有针对数据集每个特征的定义。 使用 LoadColumn 属性在数据集文件中指定源列的索引。ClusterPrediction 类表示应用到 IrisData 实例的聚类分析模型的输出。
使用 ColumnName属性将 Distances 字段绑定至 Score 列。PredictedLabelPlant做为预测显示鸢尾花类型。 在聚类分析任务中,这些列具有以下含义:
- Score 列包含一个数组,该数组中的数与群集形心之间的距离为欧氏距离的平方。 该数组的长度等于群集数。
定义数据和模型路径
返回到 Program.cs 文件并添加两个字段,以保存数据集文件以及用于保存模型的文件的路径:
_dataPath包含具有用于定型模型的数据集的文件的路径。_modelPath包含用于存储定型模型的文件的路径。
将以下代码添加到 Main 方法上方,以指定这些路径:
static readonly string _dataPath = Path.Combine(Environment.CurrentDirectory, "Data", "iris.data");
static readonly string _modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "IrisClusteringModel.zip");
要编译前面的代码,请将以下 using 指令添加到 Program.cs 文件顶部:
using System;
using System.IO;
创建 ML 上下文
将以下附加 using 指令添加到 Program.cs 文件顶部:
using Microsoft.ML;
using Microsoft.ML.Data; 在 Main 方法中,请使用以下代码替换 Console.WriteLine("Hello World!"); 行:
var mlContext = new MLContext(seed: 0);Microsoft.ML.MLContext 类表示机器学习环境,并提供用于数据加载、模型定型、预测和其他任务的日志记录和入口点的机制。 这在概念上相当于在实体框架中使用 DbContext。
设置数据加载
将以下代码添加到 Main 方法以设置加载数据的方式:
IDataView dataView = mlContext.Data.LoadFromTextFile<IrisData>(_dataPath, hasHeader: false, separatorChar: ','); 泛型 MLContext.Data.LoadFromTextFile 扩展方法根据所提供的 IrisData 类型推断数据集架构,并返回可用作转换器输入的 IDataView
创建学习管道
聚类分析任务的学习管道包含两个以下步骤:
- 将加载的列连接到“Features”列,由聚类分析训练程序使用;
- 借助 KMeansTrainer 训练程序使用 k – 平均值 + + 聚类分析算法来定型模型。
将以下代码添加到 Main 方法中:
string featuresColumnName = "Features";
var pipeline = mlContext.Transforms
.Concatenate(featuresColumnName, "SepalLength", "SepalWidth", "PetalLength", "PetalWidth")
.Append(mlContext.Transforms.Normalize(featuresColumnName))
.Append(mlContext.Transforms.Conversion.MapValueToKey("Label", "FlowerType"), TransformerScope.TrainTest)
.AppendCacheCheckpoint(mlContext)
.Append(mlContext.MulticlassClassification.Trainers.StochasticDualCoordinateAscent())
.Append(mlContext.Transforms.Conversion.MapKeyToValue(("PredictedLabelPlant", "PredictedLabel")))
.Append(mlContext.Clustering.Trainers.KMeans(featuresColumnName, clustersCount: 3));
该代码指定该数据集应拆分为三个群集。
定型模型
前述部分中添加的步骤准备了用于定型的管道,但尚未执行。 将以下行添加到 Main 方法以执行数据加载和模型定型:
var model = pipeline.Fit(dataView);保存模型
此时,你具有可以集成到任何现有或新 .NET 应用程序的模型。 要将模型保存为 .zip 文件,请将以下代码添加到 Main 方法中
using (var fileStream = new FileStream(_modelPath, FileMode.Create, FileAccess.Write, FileShare.Write))
{
mlContext.Model.Save(model, fileStream);
}使用预测模型
要进行预测,请使用通过转换器管道获取输入类型实例和生成输出类型实例的 PredictionEngine<TSrc,TDst> 类。 将以下行添加到 Main 方法以创建该类的实例:
var predictor=model.CreatePredictionEngine<IrisData, ClusterPrediction>(mlContext);将 TestIrisData 类创建到房屋测试数据实例:
- 在“解决方案资源管理器”中,右键单击项目,然后选择“添加” > “新项”。
- 在“添加新项”对话框中,选择“类”并将“名称”字段更改为“TestIrisData.cs”。 然后,选择“添加”按钮。
- 将类修改为静态,如下面的示例所示:
static class TestIrisData
{
internal static readonly IrisData Setosa = new IrisData
{
SepalLength = 5.1f,
SepalWidth = 3.5f,
PetalLength = 1.4f,
PetalWidth = 0.2f
};
}此类中的一个鸢尾花数据实例。 可以添加其他方案来体验此模型。
若要查找指定项所属的群集,请返回至 Program.cs 文件并将以下代码添加进 Main 方法:
Console.WriteLine($"Cluster: {prediction.PredictedLabelPlant}");
Console.WriteLine($"Distances: {string.Join(" ", prediction.Distances)}");
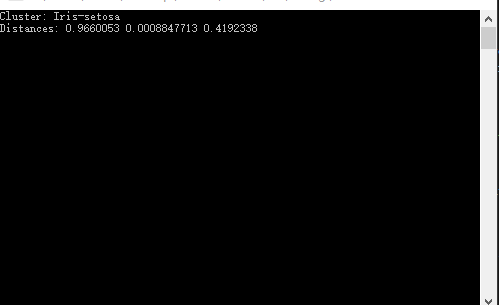
Console.Read();运行该程序以查看预测到哪个分类,以及从该实例到群集形心的距离的平方值。 结果应如下所示:
Cluster: Iris-setosa
Distances: 0.9660053 0.0008847713 0.4192338
已成功地生成用于鸢尾花聚类分析的机器学习模型并将其用于预测。
示例下载
鸢尾花分类预测示例
转载请注明:清风亦平凡 » ML.NET 来对鸢尾花分类
 支付宝扫码打赏
支付宝扫码打赏
 微信打赏
微信打赏