背景
某一个应用自动在网页上获取一些文本内容,本来是通过document.querySelector来找指定节点。经过一段时间网页貌似升级了,一些节点的class属性的值会出现随机的变动,每次class属性的值都会不一样。最初的方式就失去了作用,根据节点内容的分析发现可以通过xpath来获取。曾经在IE浏览器上使用过XPath,并且API相当简单。在非IE浏览器上貌似没有这么好用。以下内容在Chrome浏览器进行尝试,经过测试可以完成自己的预期工作。
浏览器支持
Mozilla是根据DOM标准来实现对XPath的支持的。DOM Level 3附加标准DOM Level 3 XPath定义了用于在DOM中计算XPath表达式的接口。遗憾的是,这个标准要比微软直观的方式复杂得多。虽然有好多与XPath相关的对象,最重要的两个是:XPathEvaluator和XPathResult。XPathEvaluator利用方法evaluate()计算XPath表达式。
evaluate()方法有五个参数:XPath表达式、上下文节点、命名空间解释程序和返回的结果的类型,同时在XPathResult中存放结果(通常为null)。命名空间解释程序,只有在XML代码用到了XML命名空间时才是必要的,所以通常留空,置为null。返回结果的类型,可以是以下十个常量值之一
| 参数 | 解释 |
XPathResult.ANY_TYPE | 返回符合XPath表达式类型的数据 |
XPathResult.ANY_UNORDERED_NODE_TYPE | 返回匹配节点的节点集合,但顺序可能与文档中的节点的顺序不匹配 |
XPathResult.BOOLEAN_TYPE | 返回布尔值 |
XPathResult.FIRST_ORDERED_NODE_TYPE | 返回只包含一个节点的节点集合,且这个节点是在文档中第一个匹配的节点 |
XPathResult.NUMBER_TYPE | 返回数字值 |
XPathResult.ORDERED_NODE_ITERATOR_TYPE | 返回匹配节点的节点集合,顺序为节点在文档中出现的顺序。这是最常用到的结果类型 |
XPathResult.ORDERED_NODE_SNAPSHOT_TYPE | 返回节点集合快照,在文档外捕获节点,这样将来对文档的任何修改都不会影响这个节点列表。节点集合中的节点与它们出现在文档中的顺序一样 |
XPathResult.STRING_TYPE | 返回字符串值 |
XPathResult.UNORDERED_NODE_ITERATOR_TYPE | 返回匹配节点的节点集合,不过顺序可能不会按照节点在文档中出现的顺序排列 |
XPathResult.UNORDERED_NODE_SNAPSHOT_TYPE | 返回节点集合快照,在文档外捕获节点,这样将来对文档的任何修改都不会影响这个节点列表。节点集合中的节点和文档中原来的顺序不一定一样。 |
JavaScript实现XPath选择节点
function xpathQuery(xpath){
let resultXpath = document.evaluate(xpath, document, null, XPathResult.ORDERED_NODE_ITERATOR_TYPE, null);
let result=[];
if(resultXpath){
let item;
while(item=resultXpath.iterateNext())
{
result.push(item);
}
}
return result;
}
xpathQuery("//div[@class='container-body']/div[contains(@class,'order-item')]");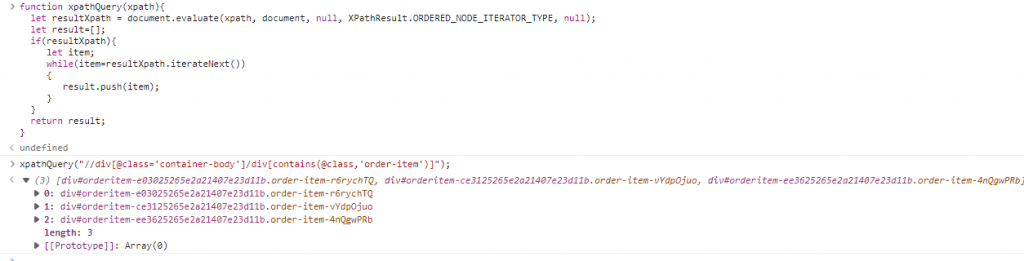
转载请注明:清风亦平凡 » Chrome浏览器中的XPath
 支付宝扫码打赏
支付宝扫码打赏
 微信打赏
微信打赏